

TECH TALK: Does the future spell the end of local news?

 Eric’s Tech Talk
Eric’s Tech Talk
by Eric W. Austin
Writer and Technical Consultant
In August of 1981, an upstart cable TV station began broadcasting these slick new videos set to music. They called it “music television.”
The first music video to air on the new channel was the Buggles’ song “Video Killed the Radio Star.” It was supposed to herald the end of radio’s dominance and introduce the world to television as a new musical medium. Instead, nearly 40 years later, music can hardly be found on MTV and radio is still going strong.
The song’s theme, a lament about the old technology of radio being supplanted by the new technology of television, is playing out again with the Internet and traditional print journalism. Sadly, the Buggles’ song may turn out to be more prophetic this time around.
The newspaper industry is currently in a crisis, and even a little paper like The Town Line is feeling the hurt.
Advertising revenue, the primary source of income for newspapers the world over, has been steadily falling since the early 2000s. Between 2012 and 2016, newspaper ad revenues dropped by 21 percent, only slightly better than the previous five years where they dropped 24 percent. Overall, in the first 15 years of the new millennium, print advertising revenue fell to less than a third of what it was pre-Internet, from $60 billion to just $20 billion globally. And, unfortunately, that trend looks to continue in the years ahead.
On the positive side, circulation numbers are up for most newspapers, and public interest has never been higher, but income from subscriptions has not been enough to compensate for the lost advertising.
 For small papers like The Town Line, which offers the paper for free and receives little income from subscriptions, this is an especially hard blow: more people are reading the paper, and there’s a great demand for content, but there is also less income from advertising to cover operating costs.
For small papers like The Town Line, which offers the paper for free and receives little income from subscriptions, this is an especially hard blow: more people are reading the paper, and there’s a great demand for content, but there is also less income from advertising to cover operating costs.
In the late ‘90s, The Town Line employed eight people: an editor, assistant editor, graphic artist, receptionist, bookkeeper and three sales people. Weekly issues often ran to 24 pages or more. Today that staff has been reduced to just three part-time employees, and the size of the paper has fallen to just 12 pages. There simply isn’t enough advertising to support a bigger paper.
People are more engaged than ever: they want to understand the world around them like never before. But as this business model, dependent on income from advertisers, continues to decay, without finding support from other sources, there is a real danger of losing the journalistic spirit that has played such an important role in our American experiment.
The reasons this is happening are fairly easy to explain. Businesses who once advertised exclusively in local papers have moved en masse to global platforms like Facebook and Google. These advertising platforms can offer the same targeted marketing once only possible with local publications, and they have the financial muscle to offer pricing and convenience that smaller publications cannot match.
This combination of local targeting and competitive pricing has caused a tidal wave of advertising to move from local papers to global corporations like Google, Facebook and Twitter instead. In the last decade, thousands of newspapers all across the nation have closed their doors. Often the first to succumb are small, local papers that have a limited geographic audience and fewer financial resources.
Like The Town Line.
There’s also been a transition in media coverage, from local issues to ones that have more of a national, or even global, audience. Websites are globally accessible, whereas traditional papers tend to have limited geographic range. Most online advertising pays on a ‘per-click’ basis, and a news story about China, Maine, will never get the same number of clicks as one about Washington, DC.
That smaller newspapers have been some of the hardest hit only makes this problem worse, as the remaining media companies tend toward huge conglomerates that are more concerned with covering national issues that have broad appeal, rather than local stories which may only be of interest to a small, localized audience.
This means that local issues are receiving less coverage, and as a result average Americans have fewer tools to make informed decisions about their communities.
When local journalism dies, what rises up to replace it? I think the answer is pretty clear: whichever website is willing to publish the most salacious stories generating the highest click-count – with little regard to proper sourcing or journalistic ethics.
Essentially, we’ve traded journalistic integrity for clickbait content.
Only a few weeks ago, the Bangor Daily News ran a story about a recent local election that may have been decided by a local ‘news’ site with no problem running rumor as news, and political partisans only too happy to propagate the dubious links through social media. Examples like this will only become more common in the years to come.
If we don’t support the traditional values of honesty, integrity and unbiased reporting that have been the bedrock of American journalism for two centuries, we may not like what rises up to replace it.
With advertising revenues hitting all-time lows nationwide, and looking to worsen in the years ahead, newspapers increasingly must rely on support from their readers to make ends meet. Since advertisers have abandoned them, it’s now up to ‘us’ to support local papers like The Town Line.
In this New Year, make a resolution to support your local newspaper. If you’re a business, help to reverse the trend by advertising in local publications. If you’re an individual, consider becoming a member of The Town Line. A small donation of $10 a month can make a world of difference. Best of all, since The Town Line is a 501(c)(3) nonprofit, private foundation, all donations are fully tax deductible!
To fulfill the American promise of an informed public, and fight the growing trend of clickbait sensationalism that has come to permeate much of the web, we must support local reporting more than ever. The time to act is now, before journalism loses another warrior in the fight for free expression.
Don’t let our generation be the one in which local journalism dies!
Eric Austin lives in China, Maine and writes about technology and community issues. He can be reached at ericwaustin@gmail.com.





 Unlike your personal computer, a driverless car is a thinking machine. It must be capable of making moment-to-moment decisions that could have real life-or-death consequences.
Unlike your personal computer, a driverless car is a thinking machine. It must be capable of making moment-to-moment decisions that could have real life-or-death consequences.
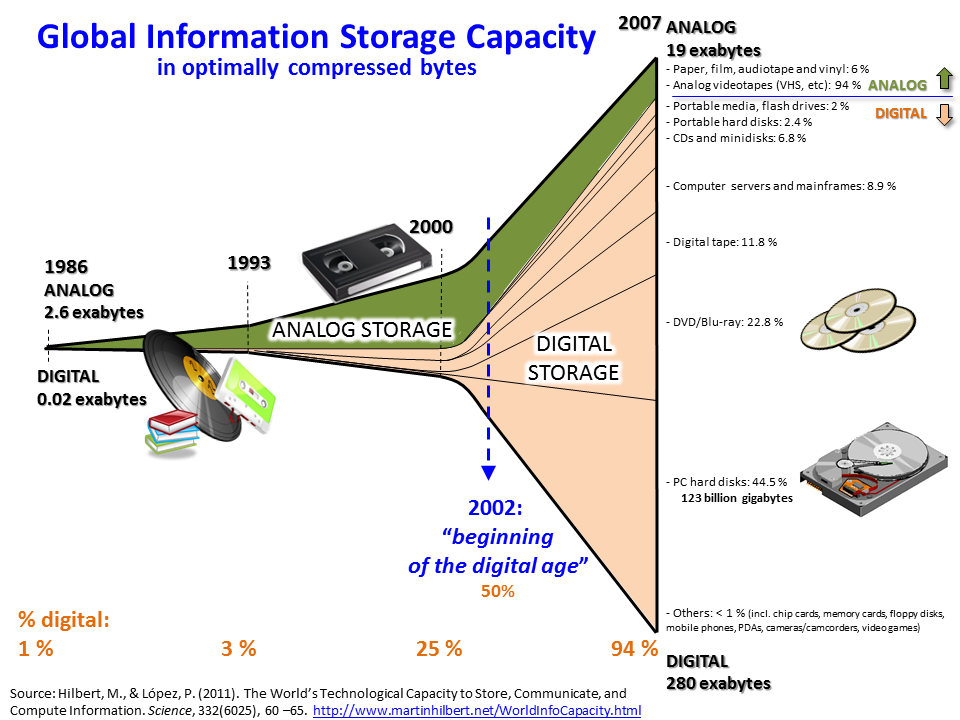
 Instead of a few grainy pictures on the front page of the Evening Post, thousands of photos and live video got posted to the internet.
Instead of a few grainy pictures on the front page of the Evening Post, thousands of photos and live video got posted to the internet.